腾讯文档是一些同事喜欢使用的产品,进行文档分享与管理,同事间共享,权限控制!总之俘获了一批经常与文档打交道的同事!但是,文档好管理,最张还得与公司的OA打 交道。于是,产生了一个需求场景,需要将腾讯文档中的Excel文件内容,同步到公司OA系统。操作步骤:登陆腾讯文档,找到Excel文件,打开Excel文件,选择导出Excel文件,执行同步程序,将Excel同步到OA.
第一回合,美好滴初步设想,自动同步。
第一时间查看腾讯文档尾部,找不到类似OpenAPI的入口,在腾讯文档的社区发起提问,得到的答复是无此接口。最美好的想法落空。
第二回合,转战自动化测试工具为我所用
自动化测试工具,主要倾向于使用python+chromedriver跑脚本来完成。而遇到一个具有挑战性的登陆状态问题,使用微信扫码登陆的话,采用自动化测试工具有些困难。最终同事们想到的方案是,一个守护进程+一个执行进程。听想来也是挺美好的,只是自动化测试的小伙伴也没有真正去做过类似的方案,一般都是从头到尾一个Case,没有一个守护+一个执行的。于是,方案悬置,未实施。

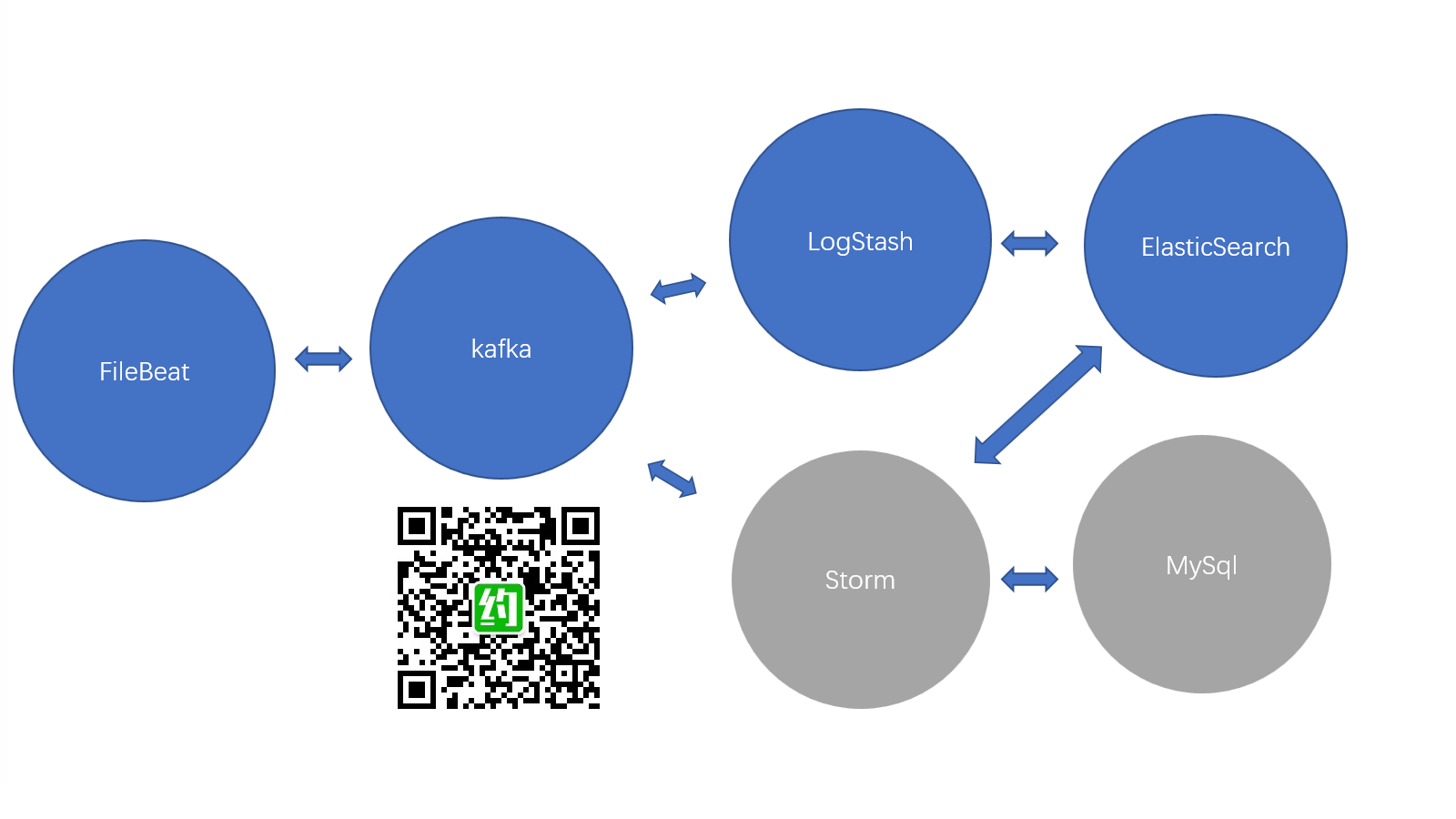
storm与财富增值
享受宜信星火金服宜心理财实现财富增值,预期年化收益10%
扫码二维码
通过宜信星火金服活动链接 http://www.ixinghuo.com/qcode.php?yixinqcode
通过宜信星火金服理财师店铺链接:https://xinghuo.yixin.com/yiidea
通过宜信星火金服理财师移动端邀请页面https://xinghuo.yixin.com/mobile/activityPage/shareShop/yiidea
5.通过宜信星火金服理财师店铺宜心理财团队短链接:
http://yixin.hk
http://yixin.ceo
http://yue.ma
通过宜信星火金服宜心理财团队网站页面
http://www.yixinlicai.com.cn
通过 宜信.公司 | 宜信.网络 | 宜信.net
第三回合,JS主战场
第二回合采用chromedriver,相比较于JS,两个方案面可抽象的理解为同一个方案。将Chrome开着,相当于守护操作,执行JS相当于执行操作。初步尝试此方案的时候,还是很开心的。JS模拟点击,直接点击导出本地excel,能实现Excel文件导向,达到预期理想。但是JS模拟需要分现两步,第一步,点开菜单,第二步,点击导出。当导出【本地excel表格(.xlsx)】存在于dom树中,这个操作是成功的。但是实际模拟场景是,先去模拟点【文件】,js普通的模拟竟然点不出菜单!!!!那意味着,得使用高级一点的模拟方式,先把鼠标模拟到指定位置,再模拟人工点击。感觉是这样子的。
第四回合,模拟精灵
JS直接模拟点击不管用,那么使用模拟精灵直接模拟点击自然是可以吧。录制模拟脚本,搜索、打开、点菜单,点导出,回放。感觉要见证奇迹了,no,no,no,那有什么奇迹,菜单还是点不出来。【感觉】模拟精灵并没有完全模拟录制的动作,存在加速执行的节奏,省略了轨迹模拟,导致鼠标停留在【文件】上方的时间不足,没有把关键动作执行好。单独录制点击菜单动作,菜单出来了。也就是,关键脚本单独录制,再合成。想想也是醉了。模拟精灵的一个问题在于,如果系统中有任何突出窗口挡住了界面,操作就断了。这种担心,可能也没有必要,关掉系统自动更新,一般莫名的弹窗也是不会有的。
第五回合,沟通神器
经过沟通,Excel导入的工作频度较低,对于自动导入来讲,实现起来麻烦!最终换成了人肉导出excel,再导入到OA。另外,要自动,不仅仅是技术上的一个实现,也是工作流程上的一个变化,将同事已经熟悉的工作方式与流程,改变掉,除非是熟悉并能改进,否则,还是用辅助工具的形式。
第六回合,Coding战场
Excel解析
使用开源的POI读取Excel真的是非常开心,想想不用安装office,不用担心进程挂起,就是各种开心。当然POI也有些让人不开心的地方,读取单元格数据的时候,会有些不太方便,int,string,datetime得严格区分开,时间读出来还有可能是数字的,所以需要做些特殊的处理。这次解析Excel有一个小小的麻烦之处,一张worksheep中一般是1个父节点多个子节点交错着出现,需要逐行扫描记录,识别出父节点与子节点,并将父节点与子节点组装起来。想不到非常顺利的解析完了~
演练
导完数据后,看起来没问题了。但是老感觉没谱。不知道数据最终会怎么使用,前前后后能否良好的串起来?这个时候,做演练是最好的选择了。还真有新的收获,之前的代码与线上代码不一致,数据库少了三个字段,上线就能崩溃。另外,导入数据还少操作了2张表。
结束语
需求是美好的,多沟通沟通,也许我们能变得更加现实。【自动】牵扯的不仅仅是技术实现,更是工作流程与工具的变更。