
Storm实时大数据windows实验
年前准备的大数据日志平台系统文章,缺少Storm环节,之前开发是在eclipse中直接跑的Storm,计划赶不上变化!Storm 1.2.2在Windows下跑得比较闹心。Storm 1.2.2 在windows 7下试玩,就是一个虐心之路,需要耐心需要一点一点排除问题。完整的看完本文,可以有如下收获:
- 能征服windows 7+Storm 1.2.2的配置
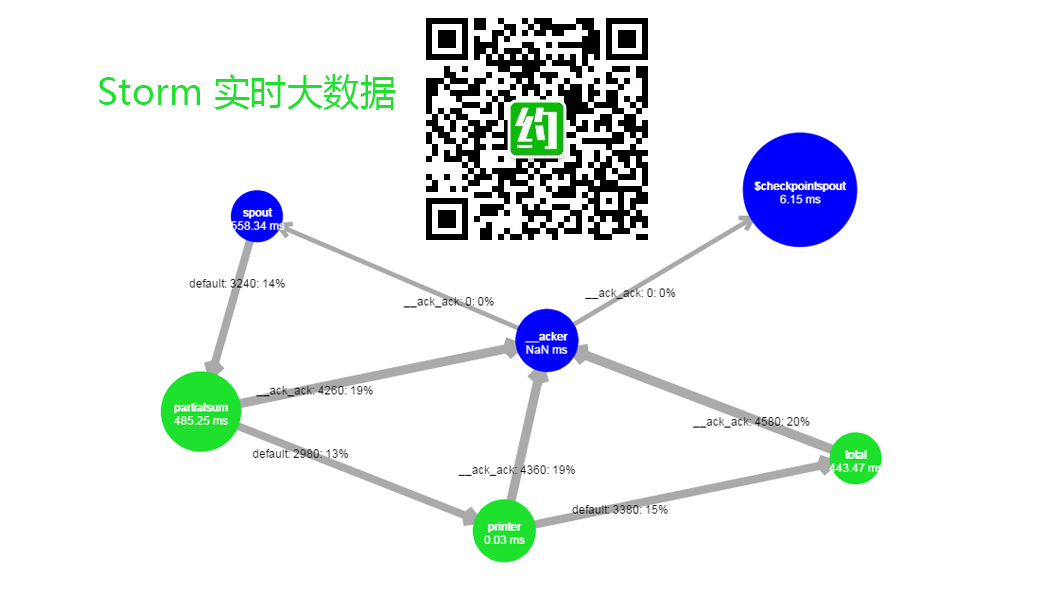
- 能跑起Storm Topology并查看拓扑的实时运行图,截取Storm Topology Visualization 图片,如本文封面。
- 收获跑storm1.2.2典型问题的三个文章链接,亲测好用,疗效显著
Docker+Linux部署大数据环境预告
年前的部署都是在windows下进行,后续将进行Docker+linux下的大数据环境配置实验,感兴趣的小伙伴可以关注本公众号。
写在前面
玩开源有一个需要重点注意的地方,不同的版本兼容性不一样,本次大数据实验是在windows 7 +storm 1.2.2 + zookeeper-3.4.12 的搭配下进行,其他环境下仅供参考。zookeeper-3.4.12部署与搭建请参考:
大型互联网平台日志系统(FileBeat+Kafka+LogStash+Elastic+Storm+MySql)小白的入门实战篇
总结如下:
一、cmd命令无法使用,跳过cmd命令,直接使用python命令
不要使用storm自带的storm.cmd,重要的事情再说一遍,直接使用storm.py去跑命令
storm.cmd提示被抛弃了,要使用storm.ps1,执行powsershel,提示问题:
$PSCommandPath为空,
Python Version 解析失败
修复方案一:$PSCommandPath为空,可升级为PowserShell 3.0 或者硬配置为当前路径
修复方案二:Python Version 使用PowerShell简单调试一下,可以修正为:
$PythonVersion = (& python -V 2>&1).ToString().Split(” “)[1];
cmd\powershell都被我跳过了,cmd,powershell一顿如狼似虎的操作,最后也是调用python,再去调java,所以直接忽略cmd/powsershell,使用如下命令:
命令执行位置:
D:\BigData\apache-storm-1.2.2\apache-storm-1.2.2\bin
常用的几个命令:
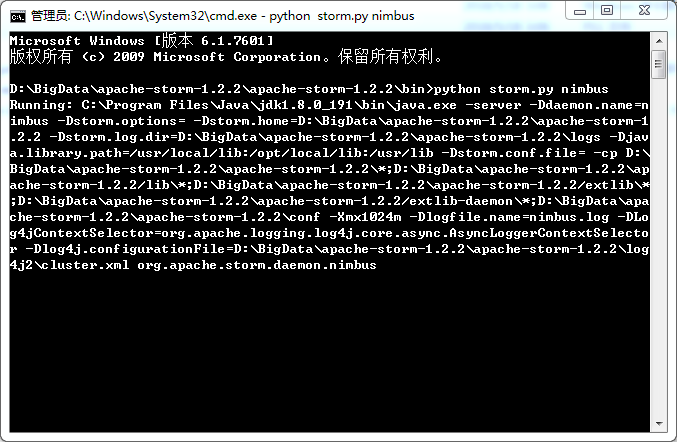
python storm.py nimbus
python storm.py supervisor
python storm.py ui
默认UI端口是8080
python storm.py jar [xxxx].jar [带命名空间的topology] [topology别名-可任性取名]
取个例子:
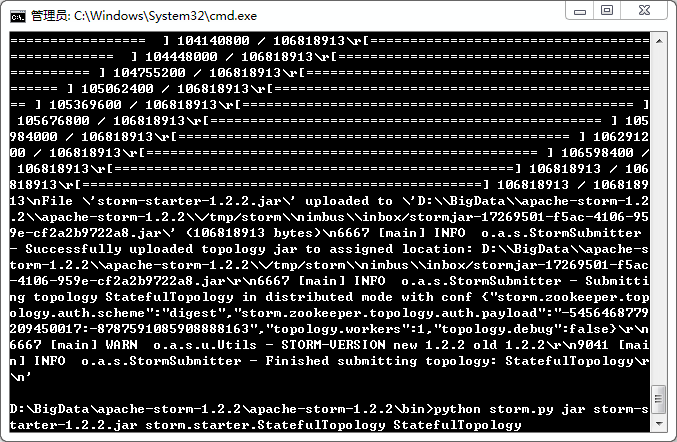
D:\BigData\apache-storm-1.2.2\apache-storm-1.2.2\bin>python storm.py jar storm-starter-1.2.2.jar storm.starter.StatefulTopology StatefulTopology
二、apache-storm-1.2.2.tar.gz自带Demo,编译不容易
apache-storm-1.2.2.tar.gz中自带了丰富的示例代码,因为太丰富了,所以问题也来了。
2.1 太多Demo,反而不利于starter
提示找不到kafka-avro-serializer-1.0.0.jar,maven中心库没有这个,需要另外配置存储库,而我只是一个starter,想快速的跑起storm,并不想kafka!
解决方案,配置maven存储库:
通常所在位置:
C:\Users\Administrator\.m2\settings.xml
修改mirrors节点
<mirrorOf>*,!confluent</mirrorOf>
增加一个新的repository
<repository>
<id>confluent</id>
<url>http://packages.confluent.io/maven/</url>
</repository>
2.2 多种开发语言支持,drpc,Too Much Under A JAR For Starter.jar
编译完之后,这个新人启航的jar包有100多mb,其实我只想是跑个超级简单的demo来看一下效果。连踩2个坑,一个是多语言能力展示,用java包裹python代码,跑不起来,一个是用java包裹node.js,也没有跑成功。本想,一个一个问题kill掉,但是网上的套路都不管用。暂时先不管Storm的多语言支持。另一个是drpc服务,二次选择topology,踩到 drpc了,配置完drpc,还是不管用,再次跳过,目前也没有这个使用场景。最后,仔细的找了一个简单的,纯java血统的topology: StatefulTopology
三、其他问题
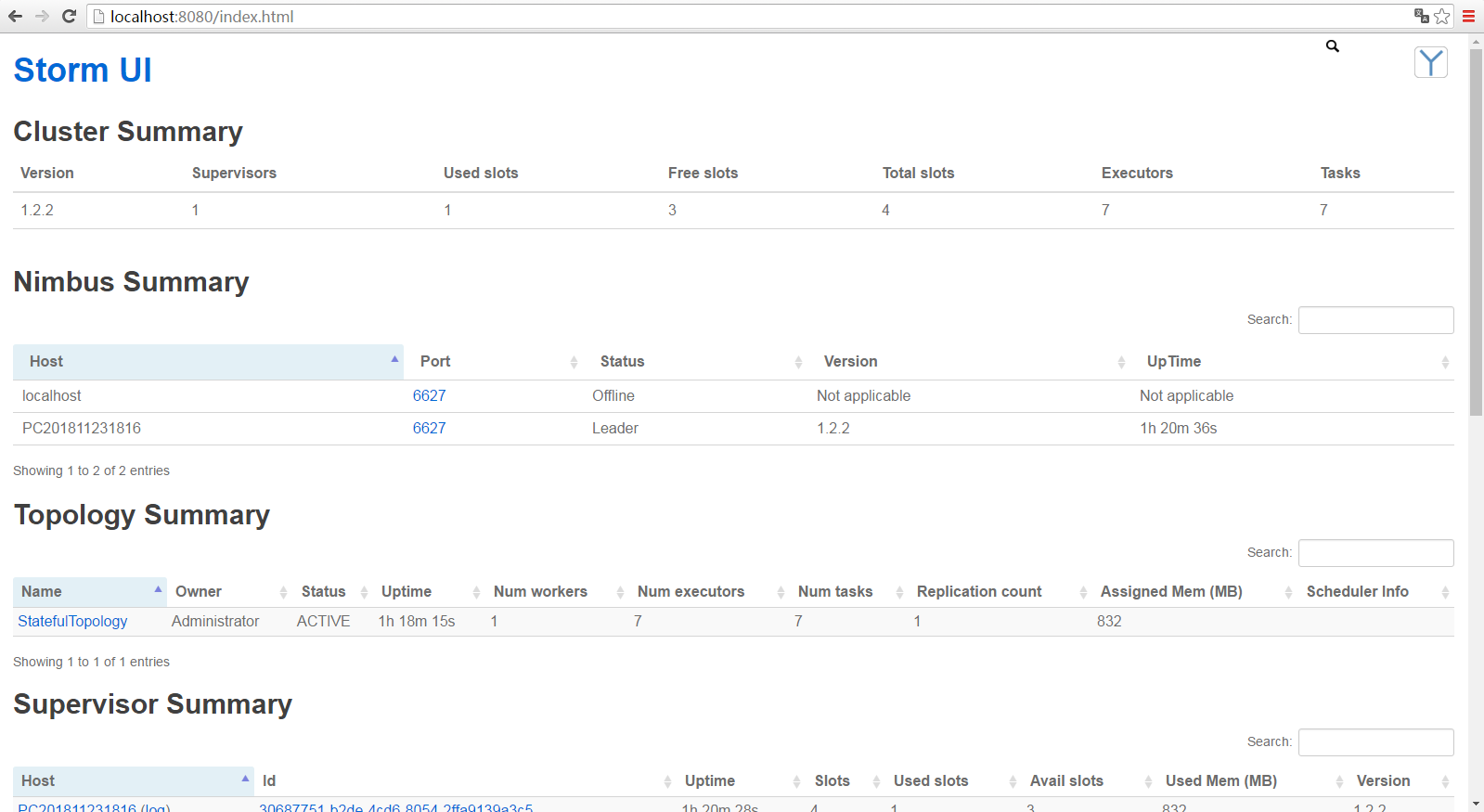
向 storm 提交 jar 包后,访问 http://localhost:8080/index.html 有时候能看到topology,但是没有节点跑。等了一会儿也没有。解决方案:将storm 中的topology kill掉, nimbus,supervisor,ui全部停了,重新提交一遍。大概在第三遍的时候出来了,懵逼的状态【可能哪一步做错了】~~截到图:
Storm实时大数据windows实验
2.3 又见PowerShell
storm.ps1的错误提示,真心不够友好!为了检测python版本是否符合要求,写了好几行ps代码,结合ps代码本身也有版本要求。
$PSCommandPath 为空,代码直接报错
这段ps1 ,应该有提示ps版本问题。
或者,应该是有一个前置安装检查的脚本或工具,引导玩家或自动处理前置安装问题,这样子才会更加好友。这个方面微微软的sqlserver安装向导就做得比较好~
PowerShell 未经数字签名 系统将不执行该脚本
set-executionpolicy Bypass
写在后面
python storm nimbus这种命令方式是同事告诉我的,不然还在坑里爬。本来windows 7 + Storm就是非常规的组合,只是想把windows系列的文章写全了,跑通,所以才挣扎了这么久。感觉从事开源,就像一个自己的舞台,大家很努力的做一个storm,别人用得是那么的闹心,虽然官方提供了那么多文档那么多示例。storm.cmd , storm.ps1的提示真心留下了阴影。期待下一波Docker+linux玩转大数据吧,同样是zookeeper,filebeat,kafka,storm,elasticsearch等,一步一步亲测,全部跑通!

参考链接:
找不到kafka-avro-serializer-1.0.0.jar
https://stackoverflow.com/questions/43488853/confluent-maven-repository-not-working
PowerShell版本问题