
写在前面
Storm实时分析系列文章已经有多篇了,每篇的重点不一样,今天的Storm文字直播分享的是Storm实时分析过程中的延时处理。在整理Storm 探针的过程中,发现Storm涉及的知识点还是很多的!最近所做的Storm工作都是基于Low Level API开发,而官方显示还有Tident高层次接口,数据落地方案也有不同的实现方案。在这里分享的是实战的心得,不一定是最佳的处理方案也不是实际落地方案,而是包含个人色彩的理解模型方案与实战方案的融合,仅供参考。
一天一收获
作为一个有态度的Storm经验分享者,先给大家介绍一下阅读完全文可以收获的知识点:
- ES落地优化经验
- 落地频率的取舍之道
- 实时数据呈现的Topology设计
业务背景
本大数据Storm业务背景是基于链路跟踪的日志分析处理,呈现出链接实时响应状态(正确率,调用关系,平均响应时长等等),链路跟踪的日志标记了同一请求的日志,同一请求日志有一样的跟踪标识,并且日志记录分收发时间。每个业务的请求调成关系图要实时计算出来。
日志特征
1.收发日志为2条日志,意味着时长计算需要将日志合二为一
2.链路跟踪为多条日志,意味着要从多条日志中生成调用关系
3.ES最初设计统计结果存储跨度为分钟,即每个接口的统计状态都是按分钟存储统计数据,每分钟的调用次数、总消耗时长
第一版 Topology
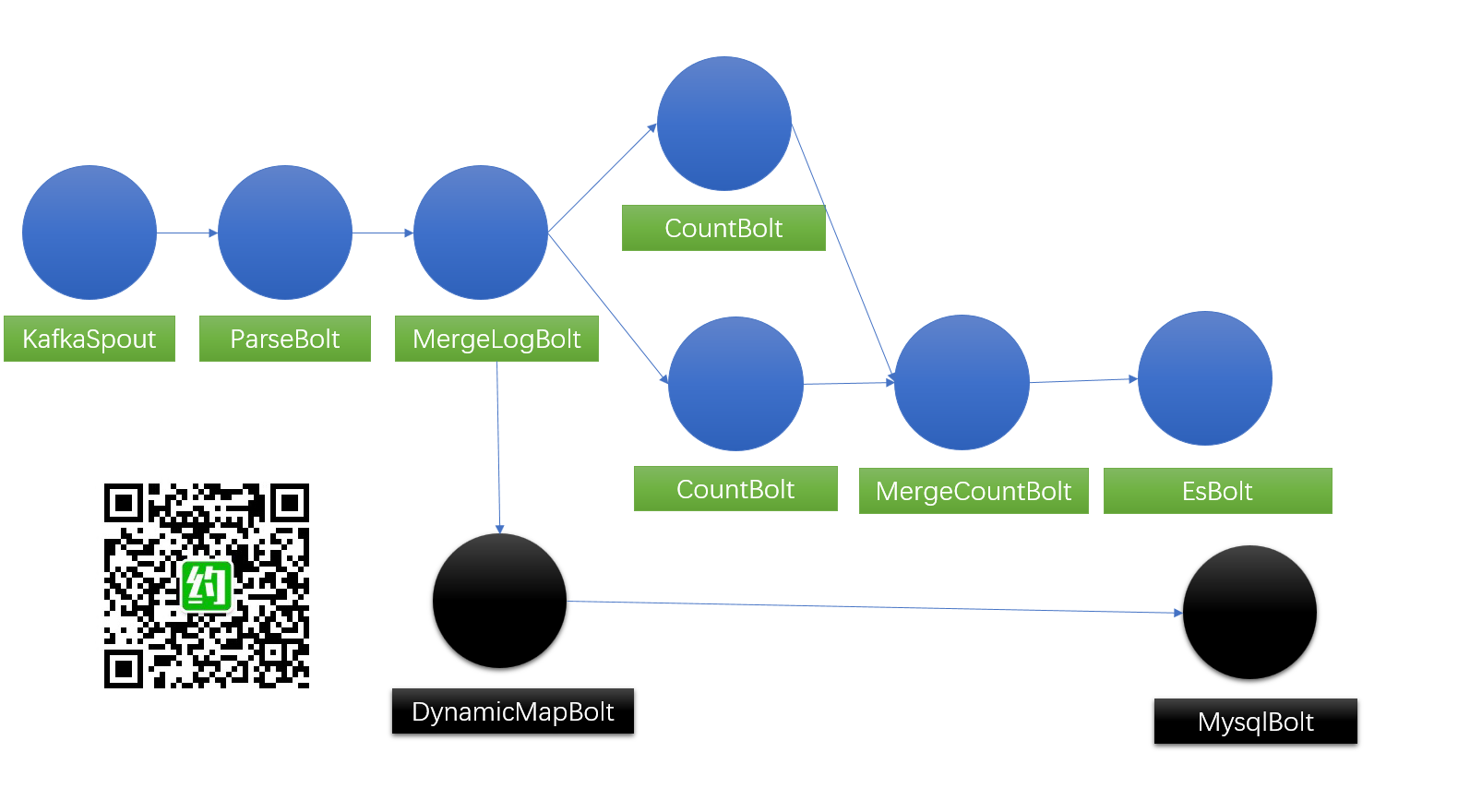
第一版Topology的处理满足了基本数据呈现指标,调用关系图生成、正确率、平均时长都能计算出来。美中不足之处在于,数据是合并到分钟存储,为了确保日志处理到分钟,设置了一定的时间窗口,等日志统计完再写到ES。时间窗口的设计导致查看到的数据存在延时。
实时性优化
优化方案有两种,一是调整ES落地频率,提升实时性,同时改造查询接口,将每分钟的结果合并处理!二是借助Redis等内存解决方案,将查询结构分成内存区以及ES区。方案一相对更好实施,只需调整落地频率,并改查询接口做调整,方案二则需要引入新的内存解决方案。虽然没有选用方案二,但是个人还是更倾向于方案二。
ES采用批量插入模式,效率会更高,否则日志处理速度会很慢。实战经验显示,逐条插入几个小时,批量插入可能几分钟。
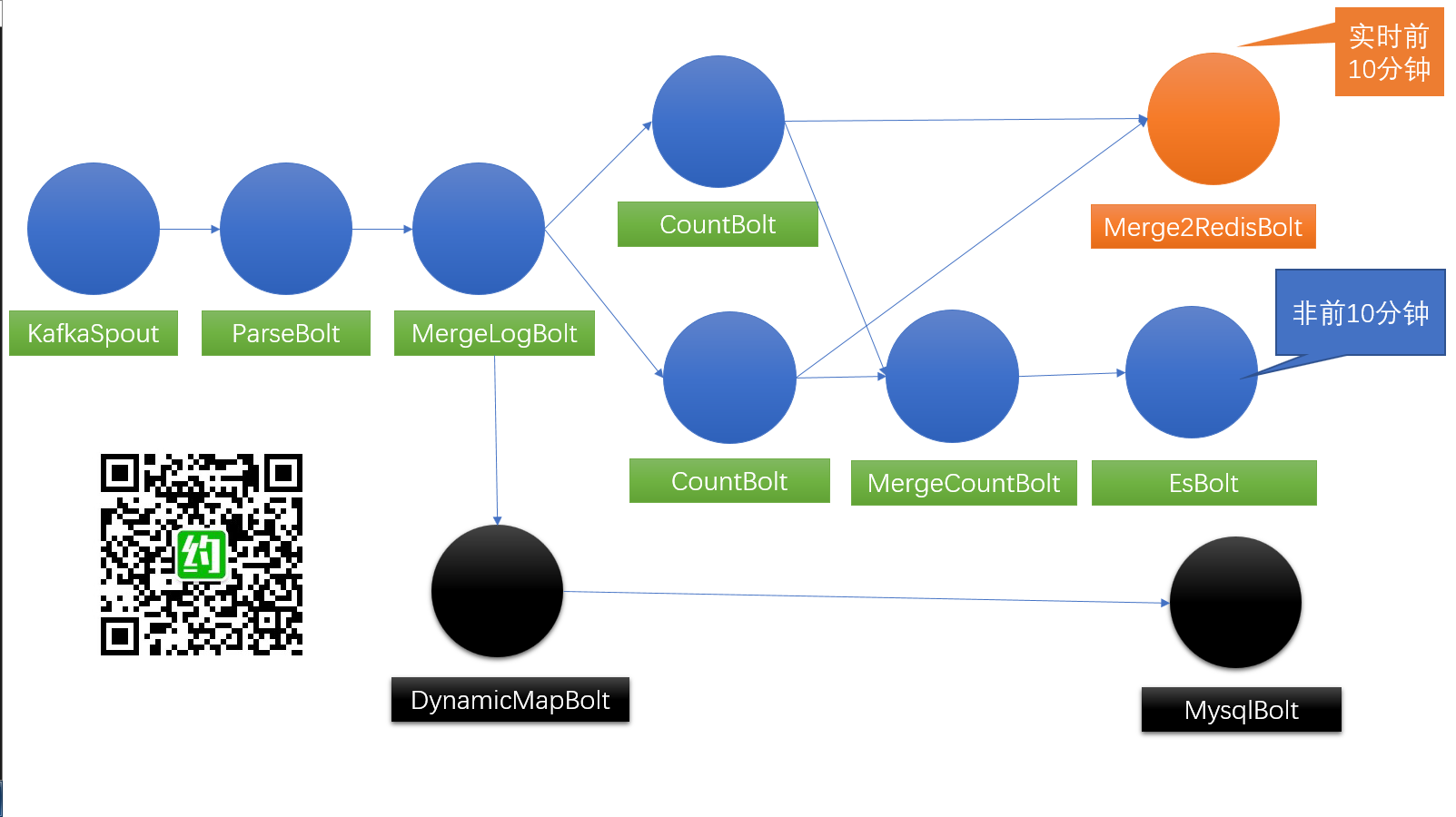
升级版 Topology 【Dream Version】
方案二利用了redis存储统计结果,落地ES的数据还是按分钟存储,不会像方案一,一分钟数据可能产生多条统计数据。从存储上、实时性上,方案二都更加完美。方案一的频率会影响ES存储量,所以采用方案一的话,落地频率是把双刃剑,得有所取舍。方案二则会更加灵活,不会增加ES存储负担。
The End
目前来讲,还没有在正式环境运行,我们也算是在吃Storm螃蟹,是否应用得当,也要更进一步的看运行效果。实时性的要求,也要看业务运用的情况。优化也是一个需要探索的事情,今天就先到这里。
预告
近期会推出
Docker+Linux+FileBeat+Kafka+LogStash+Elastic+Storm+MySql
系列部署实战文章,关注公众号,每天进步一点点。
