大数据实时日志系统搭建
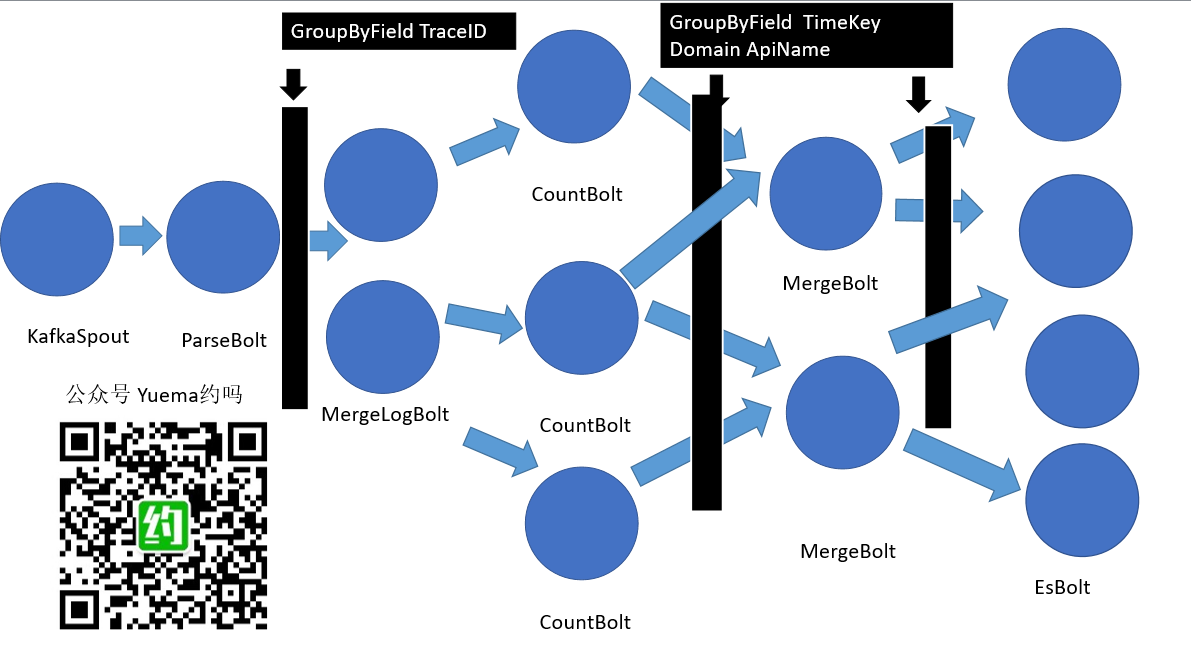
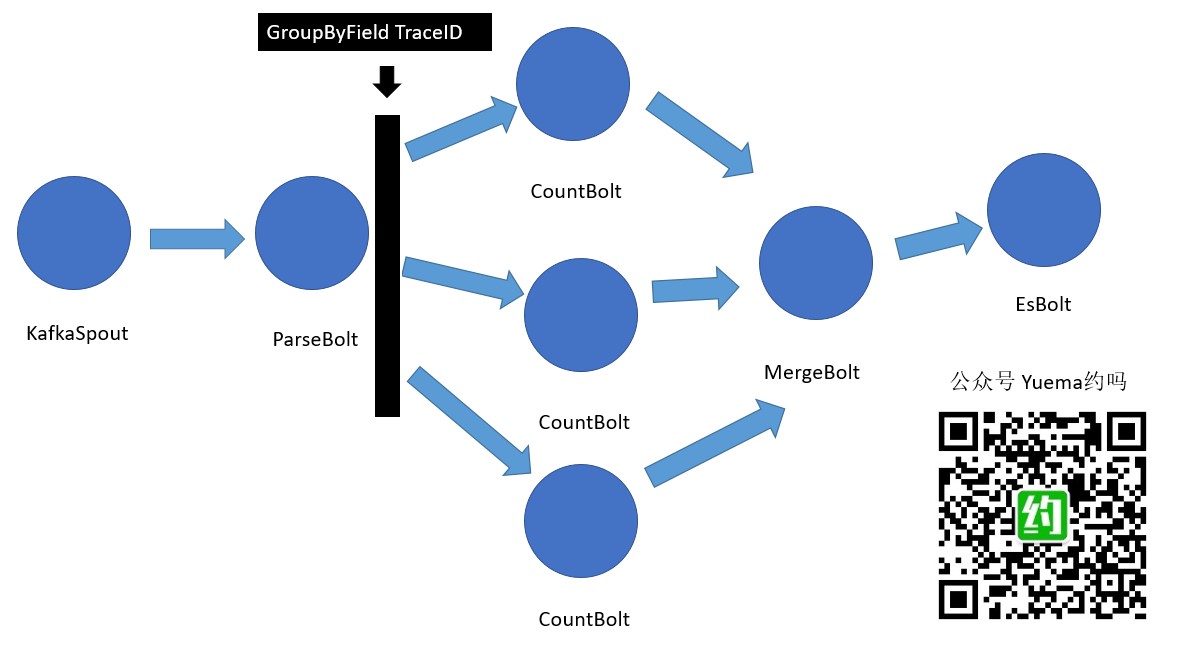
距离全链路跟踪分析系统第二个迭代已经有一小阵子了,由于在项目中主要在写ES查询\Storm Bolt逻辑,都没有去搭建实时日志分析系统,全链路跟踪分析系统采用的开源产品组合为FileBeat、Kafka、LogStash、Elastic、Storm,外加自主前端、自定义日志。今天挤出时间,选用FileBeat、ElasticSearch、Kibana搭建了一个实时日志系统。搭建之前,看了一下Elastic Stack产品组织中的LogStash,一般建议FileBeat输出到LogStash,再由LogStash到ElasticSearch,今天的实操并没有使用到kafka、LogStash、Storm,这是明天的主餐,感兴趣的可以关注公众号,明天接着看。
看完本篇文章,您可以有以下收获:
a)您能够搭建一个实时的日志分析系统,并能知道如何处理遇到的问题。
b)您将了解Elastic+Kibana在日志分析、商业大屏、航空看板、商业分析的应用,并能结合自身公司的业务情况,有选择的为公司实施大数据,提升公司的数据价值挖掘能力。
c)看不懂,包教包会
作为一篇有态度的技术文章,先把本次实操感受写在前面。
一、ElasticSearch-head揪心之作
1.1 揪心之作
部署完ElasticSearch,没有UI界面,这跟很多开源产品的现状很像,apache出品的不少开源产品,好多UI也是丑丑的。elasticsearch-head作为ElasticSearch UI的空白,算是一个惊喜,在Github上获得了5000多个星星,梦想中的星星数量啊。揪心的是,用起来,就是有点不爽啊,滚动条拖到尾部才能找到,也是丑丑的~复杂查询也是不够好用~![]()
1.2 部署经验
npm install跑不成功,yarn install成功跑起来。最好将源改为国内大厂源,不然,应该是直接失败吧。
1.3 开源收获粉丝还是存在很多机会
ElasticSearch-head弥补了ElasticSearch UI确实,还有优化空间。kibana也有完善空间。
二、安全问题也许就是网上教程传出来的
ElasticSearch默认不允许跨域,网上查到的解决处理是
http.cors.enabled: true
http.cors.allow-origin: “*”
对于正式使用的话,还是有些风险的。自己玩弄着完是可以,真正使用的话,要限定一下。这招防君子不防小人。
三、完美的不可用产品kibana
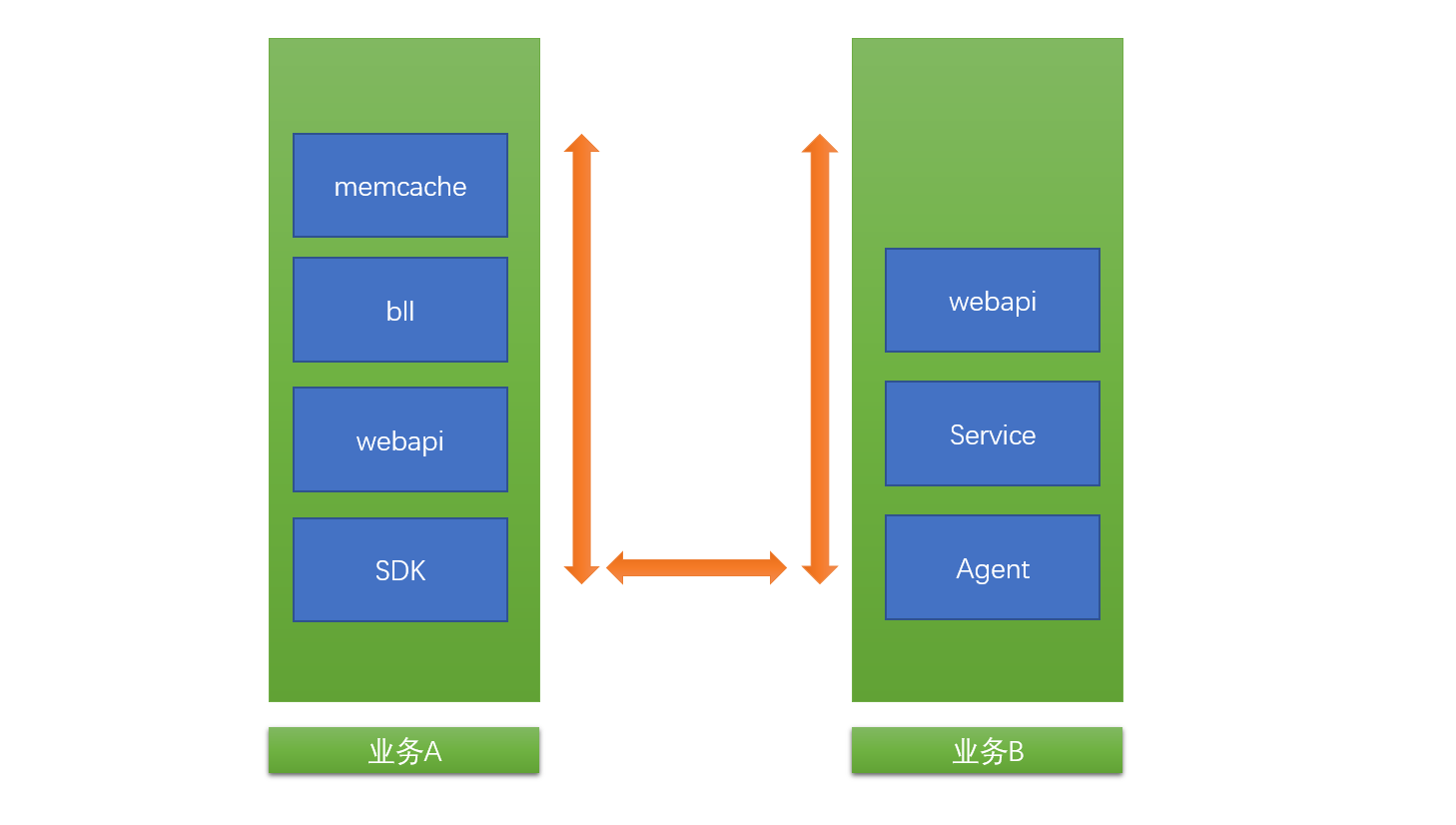
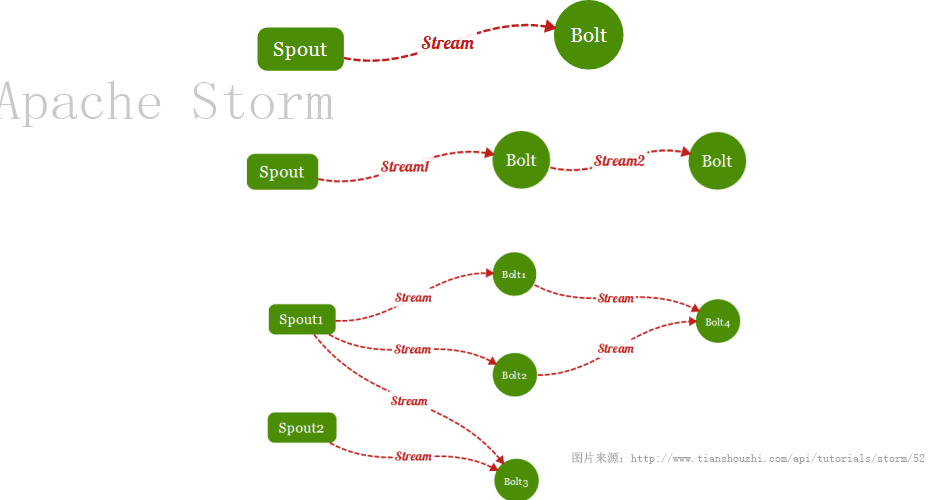
这么说可能会引起kibana粉丝的不爽,对于一个全链路跟踪系统来讲,kibana真的是满足不了,kibana有着非常漂亮的UI,灵活的可视化呈现,却无法适应我们的业务场景,或者说,就着kibana的话,会付出更多的二次开发成本。kibana有着丰富的可视化组件,却没有我们所需的调用图。全链路跟踪分析系统没有使用kibana,而是自主研发的前端。
kibana有对于现有产品IIS\Apache\Mysql\服务器等等,都有数据采集组件,可以对系统所采用的软件进行监控。对于特定的业务,需要二次开发,比较复杂的业务的话,需要在kibana基础上进行二次开发,会比较麻烦。
四、FileBeat只是Beat产品中的一个
今天看资料才发现,Beat产品组中还有很多,FileBeat只是其中一个,目前完整组合是Filebeat,Metricbeat,Packetbeat,Winlogbeat,Auditbeat,Heartbeat,Functionbeat!全方位收集日志,监控无所不及。![]() 我们只用FileBeat~
我们只用FileBeat~
五、跑开源产品不要怕报错
虽然会吓一跳,但是仔细看提示,还是能看到错误提示中给出的解决办法。
5-1. 跑FileBeat收集IIS Log时,会发现,ElasticSearch中查到的结果显示正则解析失败!
因为默认的grok规则配置是记录所有IIS字段,而IIS默认的log没有输入所有的字段,打造IIS站点日志配置,将其他没有输出的字段都勾选上。
尴尬:grok的正则写法丢到Match Tracer(一个正则调试工具)中,直接懵圈了,放一条日志进去匹配不到。字段对不上。
配置现场:
filebeat-6.5.4-windows-x86_64\module\iis\access\ingest\default.json
除了iis module,还有很多丰富的module备选,apache2,auditd,elasticsearch,haproxy,icinga,iis,kafka,kibana,logstash,mongodb,mysql,nginx,osquery,postgresql,redis,suricata,system,traefik
5-2.使用IIS module,要开启相应的插件
不要慌,报错上面有提示,跑2条命令。玩开源啊,要有看报错的准备,从报错中看答案。看不出来再去搜索~
六、where is Ambari
Apache Ambari能傻瓜式的部署安装Hadoop,Elastic系列产品少了一个类似的产品。对于开源届来讲,不了一个统一的傻瓜式部署平台。如果有的话,请留言告诉我哈~
七、where is 智能调优
一堆产品组合成一个解决方案,人肉调优好心碎,也不专业。
八、 Kibana机器学习初感
初看,是看不出什么内涵,就罗列了一堆维度,看不出什么机器学习的能力。好像一个营销噱头,也可能我没有看到kibana的机器学习功力。
能坚持看完吐槽的小伙伴,真的是铁丝。接下来会将本次实验的步骤截图展示出来。很多都是网上可以查到的!![]() 也不要太失望,我截了不少效果图,对于不想动手搭建环境的老铁,可以直接看效果图,再决定要不要玩起来。
也不要太失望,我截了不少效果图,对于不想动手搭建环境的老铁,可以直接看效果图,再决定要不要玩起来。
部署说明,本次搭建的实时日志分析系统用到了FileBeat,ElasticSearch,Kibana,都可以从官方网站www.elastic.co直接下载。elasticsearch-head请从github上下载。基本上都是开箱即用的,只有少部分要调整,依据我的部署说明来,应该能通关,如有遇到解决不了的问题,也要可以在公众号中留言提问,我会解救你。
部署步骤:
前置:安装jdk,我用的1.8版本,自行安装解决。
- 安装elasticsearch-6.5.4
- elasticsearch-head
- kibana-6.5.4-windows-x86_64
- filebeat-6.5.4-windows-x86_64
不要怕,都是解压出来就能跑
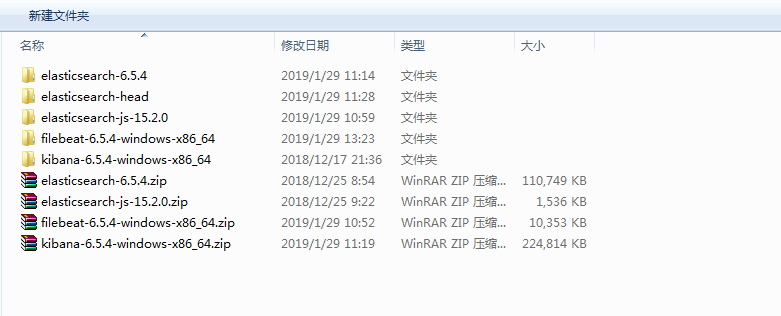
大数据实时日志系统搭建文件目录
1.安装elasticsearch-6.5.4
解压出来,跑 elasticsearch-6.5.4\bin\elasticsearch.bat
跑完,可以查看localhost:9200,能查看到类似以下界面!纯接口,人类表示无法看,于是要安装一个elasticsearch-head,类似一个管理查看的。
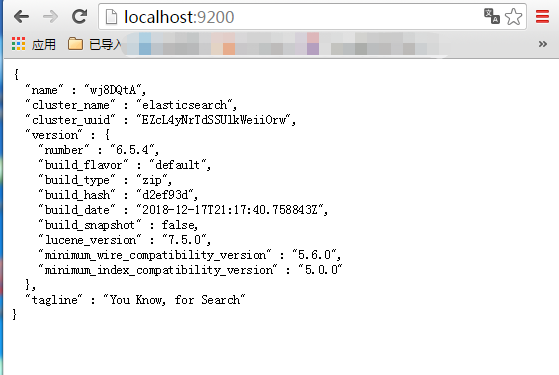
elasticsearch_9200安装成功效果图
2.安装elasticsearch-head
将https://github.com/mobz/elasticsearch-head
克隆或者下载到本店,下载一个node.js,安装好
因为这个东东需要用到node.直接到node.js上下载一个,一路next,就安装好了node.js。
cmd进入到elasticsearch-head的目录
依次输入
yarn install
yarn start
命令说明:yarn install是恢复elasticsearch-head引用到的包,yarn start是用于启动。当然,也可以使用npm install,npm start,最终效果是一样的,如果你没有安装yarn的话,可以用npm。因为资源可能在国外,所以执行命令会慢,等一等,如果失败的话,请更换成国内的源。(可以搜索,也可以来问我哈)
见证奇迹的时刻来了:
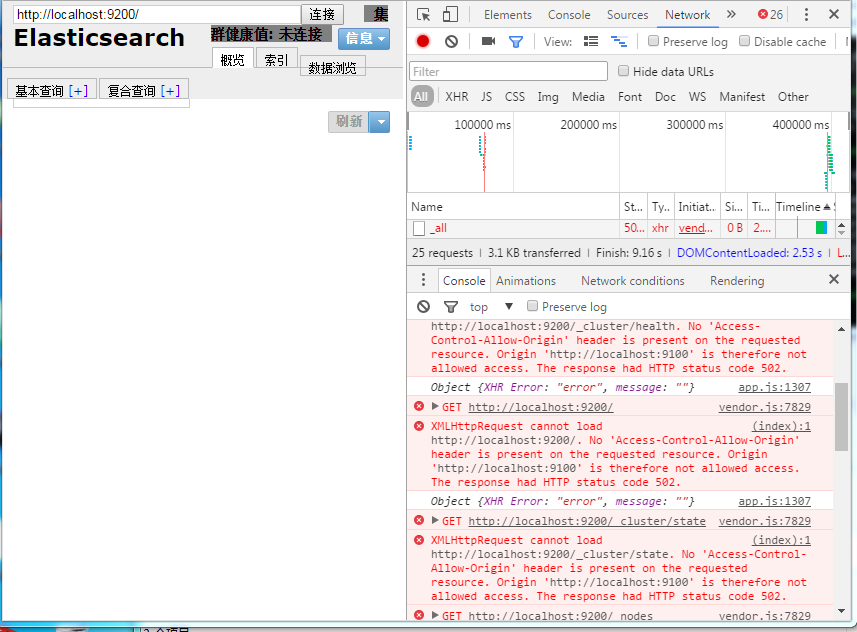
elastic-header-cors_problem
报错了,提示跨域了。解决方案:修改elasticsearch-6.5.4\config\elasticsearch.yml,增加:
http.cors.enabled: true
http.cors.allow-origin: “*”
备注:这里用的是*,如果用于生产环境,建议写具体的URI
处理完的效果图
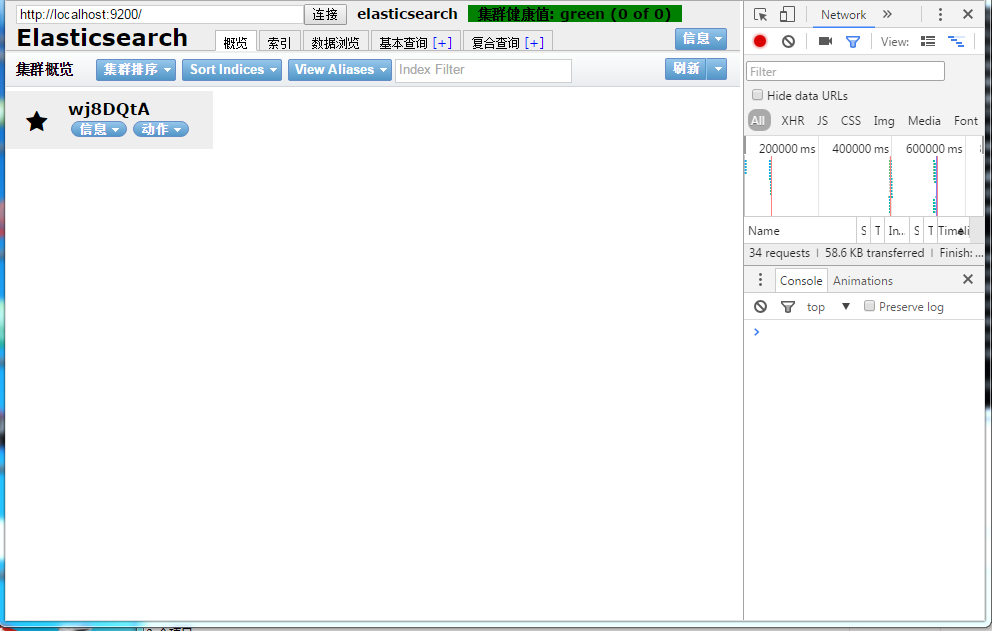
elastic-header-cors_ok
3.安装kibana-6.5.4-windows-x86_64
解压后执行命令 kibana-6.5.4-windows-x86_64\bin\kibana.bat
进入http://localhost:5601/ 查看kibana,进入是空白的,kibana自带了一些示例数据,在里面点点点就找到了,进入Dashboards
- eCommerce
- Logs
- Flights
官方示例数据是三大领域,商业、日志、航班,覆盖了多数场景,可以照着官方的示例完成自身的业务需求。
4.filebeat-6.5.4-windows-x86_64
Filebeat收集IIS有点小插曲,不碍事。
将filebeat-6.5.4-windows-x86_64\modules.d\iis.yml.disabled 改名为 iis.yml
跑不起来,但是有提示。就像问道游戏,每个任务都会有明确的提示,不会晕菜。
小插曲来了,elaticsearch中的抓到的日志,message中显示解析失败,日志没有按一个一个字段存下来,而是一整条,看起来怪怪的。怎么破?
到IIS中,选择站点,右则会有日志,点开,选择字段,全部选上。
配置完,就能正确收到IIS日志信息了。
这就是我选这个图当封面的原因,坑啊。
怎么不断产生访问日志?
写一个.bat文件,多点开几个,跑着就好了。
:S
echo hello world
curl http://www.yue.ma
goto S
效果图
安装部署流程讲完了,不懂的地方可以随时留言!喜欢看效果图的小伙伴有福了,我截了不少kibana的效果图,一起来看看吧!效果图后面,还会分析一下,为什么kibana效果也不差,而且还是开源的,我们为什么不用kibanan
Kibana用来全方位监控服务器、数据库、网络状态、商业数据等等都是不错的选择,但是我们的全链路跟踪分析系统需求有些特殊,需要对各站点日志请求进行分析,归到不同的业务上,并依据日志生成调用关系图。这就是实时日志系统搭建从入门到放弃的来源,因为明天会升级方案!
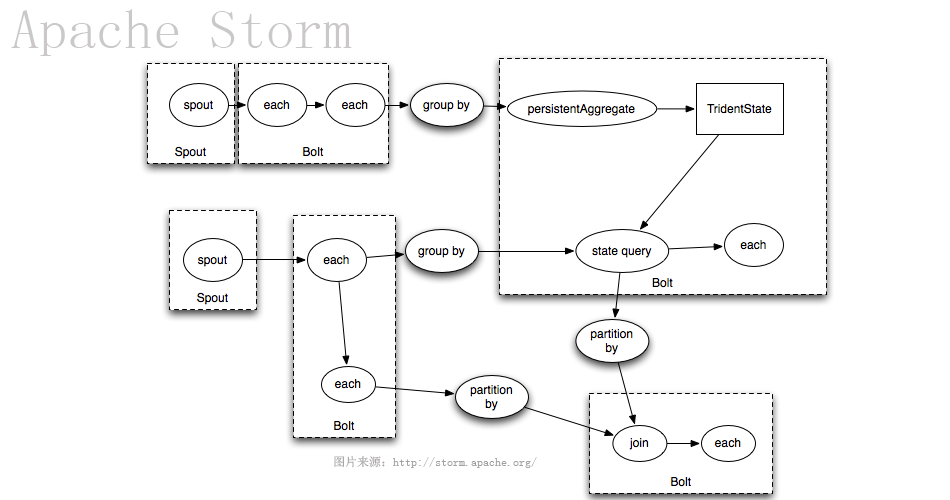
明天将介绍FileBeat+Kafka+LogStash+ElasticSearch+Storm,全链路分析系统的大数据日志环境搭建!敬请关注明天的大数据日志分析实战图文直播!