
巧妙拆分bolt提升Storm集群吞吐量
项目背景介绍:
我们通过日志系统跟踪每个接口的运行状态,收发时间,平均速度,成功率,平均响应时长。日志被收集到了kafka,日志实时处理采用storm框架。一个请求有一条服务接收日志,一条服务器响应日志。需要通过日志实时处理,统计出每个接口的每分钟的指标,存到ES。
昨天的Topology图画成这个样子,如果有看过昨天的文章的话,应该还有印象。
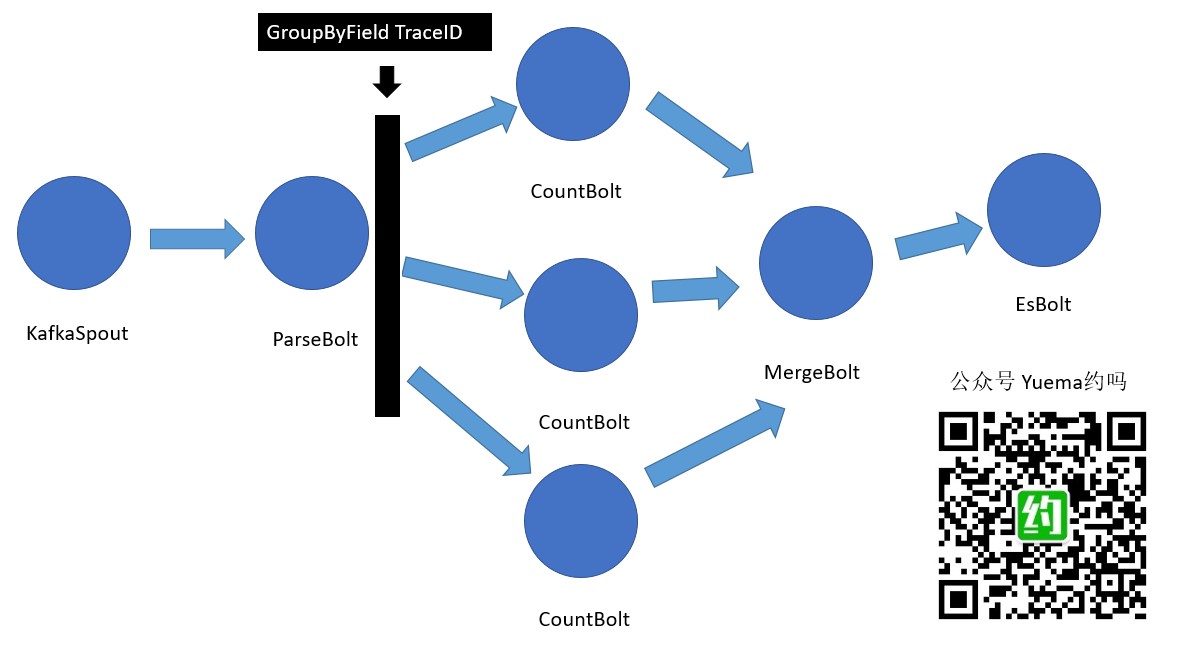
Storm & kafka 日志统计代码流程转成多个Bolt
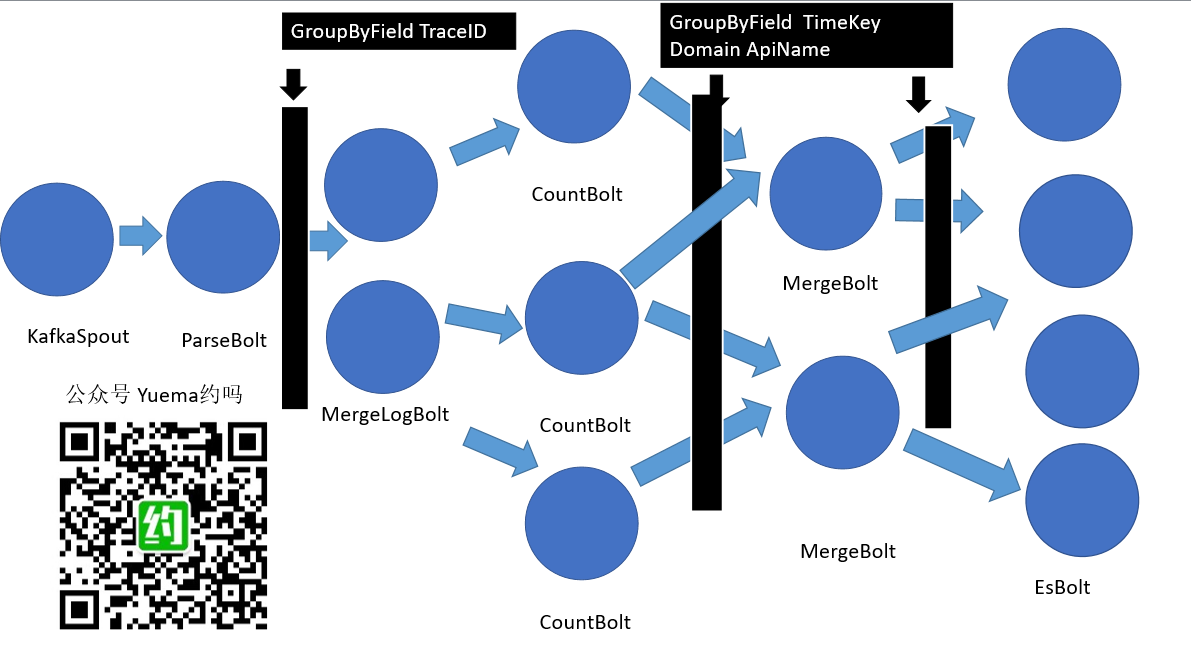
昨天写文章的时候,就思考要不要将CountBolt拆成MergeLogBolt加CountBolt,原来在一个CountBolt中即要做日志合并,又要做统计。今天整理代码的时候反复的思考,考虑到并行度的、代理管理维护、协作开发,多个维度,同时也考虑代码逻辑清晰度,果断拆开了。所以今天的图变成了:
巧妙拆分bolt提升Storm集群吞吐量
如果细心看的话,每一个bolt都可以调整并行度了,可以依据每个bolt的处理速度配置合理科学的并行度。比如,要是EsBolt慢,可以增加EsBolt并行度,如果EsBolt并不是瓶颈所在,一个EsBolt也可以的话,可以配置为并行度为1。同时还可以考虑调整bolt之间的流控制,综合日志特点再调整并行度配置,从而提升集群处理的吞吐量。
目前我们拆分的Bolt细化到了PareBolt,MergeLogBolt,CountBolt,MergeCountBolt,EsBolt,划分原则如下:
1、单一职责,每个Bolt仅做一件事情。比如MergeBolt,CountBolt,原来是划到一个CountBolt,进行代码梳理的时候发现,MergeBolt需要维护一个组装log的HashMap,并要定时进行清理一定时间窗口未组装成功的孤立日志,组装成功的要及时从HashMap 中删除。而CountBolt维护统计数据是按timeKey,域名、业务名来组织 HashMap,时间窗口的处理逻辑完全不一样。对于MergeLog来讲,组一个删除一个,再定时清理孤立日志就好。而CountBolt则不一样。感觉夹杂在一起,给同事介绍起来也费劲,代码组织也不够清晰。拆成两个bolt之后,感觉代码逻辑更加清晰了。也更好的利用Storm提供的实时计算能力,可依据计算情况,为每个bolt设置相应的并行度,达到更高的吞吐量。简单的来讲,就是将一个大的逻辑,拆成一个一个小的逻辑,用tuple串起来,每个bolt都有明确的输入tuple,明确的输出tuple,也好进行代码逻辑问题定位。
2、协作原则,相对于在一整串代码逻辑中去写逻辑,别人读懂代码会更加费劲,往往是懵menbelity,而划成一个一个bolt之后,一个bolt的逻辑更加简单好懂。每个Bolt拿到tuple只做一件明确的事情,可以更好的并行开发。大家只要约定好输入的tuple,产出的tuple。比如,我们将Es操作划成一个Bolt,落地数据的小伙伴只要专注于Es操作,做合并的小伙伴只要专注于合并。哈哈,是不是很神奇。
收尾,这是一天下来的工作心得,对bolt的划分经验也是经过不断进行代码整理思考的结果。开始是在一个bolt里完成业务所需的所有逻辑,之后才拆成一个一个bolt来对待,并不是一上来就拆成一个一个bolt,第一天的时候比较担心日志无法成对的问题,所以都不敢拆,实验完GroupByField之后才敢拆。这个是有一个过程的。首先要知道业务要干什么,打算怎么实现,拆的话会引起什么问题,怎么解决,经过同事的指点与摸索,算是有了些心得,至少现在拆分出的几个bolt,基本上感觉是OK,已经是拆到一个合理的地步了。当然我也是刚玩Storm,如有好的bolt拆分心得,也欢迎指点,欢迎分享分享。

巧妙拆分bolt提升Storm集群吞吐量