
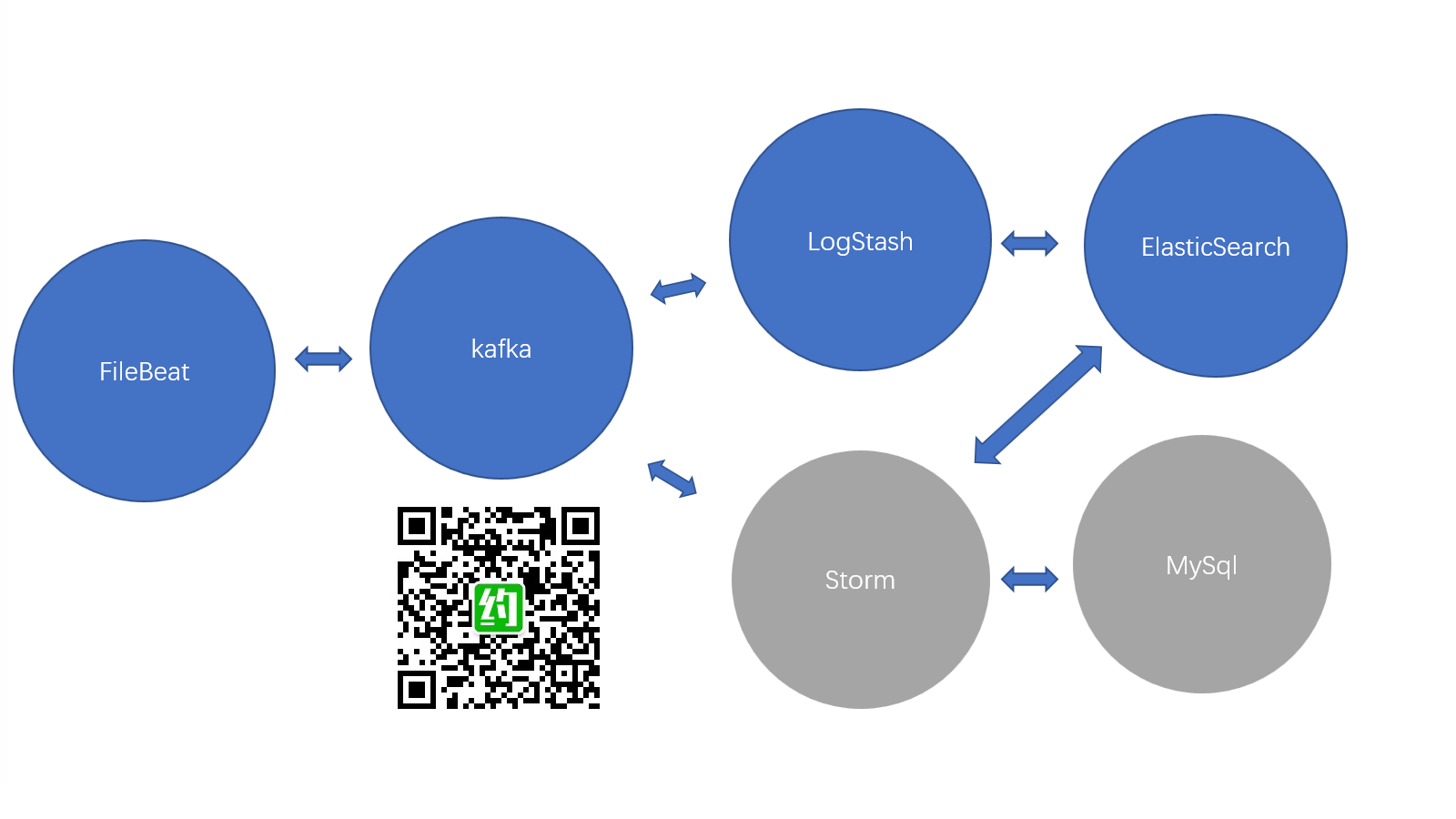
大型互联网平台日志系统(FileBeat+Kafka+LogStash+Elastic+Storm+MySql)小白从入门实战篇
原计划昨天的公众号图文直播因公司年会抽奖而没有进行,今天在自己的电脑上实战了FileBeat+Kafka+LogStash+Elastic+Storm+MySql的环境搭建,由于今天的实验过程并不顺利,所以整体实验方案砍掉了Storm、MySql,这将是明天的套餐。
作为一个有态度的资深公众号运营人员,写一篇文章不仅会为了达到原创标准凑够300字,同时也会把本次实战的心得与经验放到前面,让小伙伴能以最快的速度收获一些经验性的东西。同时,实战是一步一步操作,并跑并跑起来,是在坑里爬了很久,才写出来的,如果你有兴趣可以照着做一篇,是可以跑起来。看不明白的,可以留言问,包教包会~![]()
![]()
![]()
![]()
完整的读完本实验总结,可以有以下收获:
- 能搭建互联网平台日志收集系统
- 能知道如何处理开源产品配置报错
本次实战的小心得如下:
- 玩开源产品,版本多,不要怕提示出错,网上多找找,一般都能找到答案。
- 这不是在堆代码,只是使用开源的产品,不需要编程功力。
- 先了解一下相关产品的设计思路,用得思路会更好些
本次实验用到的开源产品:
elasticsearch-6.5.4
elasticsearch-head
filebeat-6.5.4-windows-x86_64
kafka_2.12-2.1.0
logstash-6.6.0
zookeeper-3.4.12
autovisit.bat (![]() 这个一小段脚本,用来不断访问页面,以产生访问日志,自己DIY也可以,很简单。加头我放到Github上吸粉
这个一小段脚本,用来不断访问页面,以产生访问日志,自己DIY也可以,很简单。加头我放到Github上吸粉![]()
![]()
![]()
![]() )
)
本次实现新增加了Kafka\LogStash\zookeeper,先来看一下实现录的小视频,直观的感受一波操作。
关注公众号 Yuema约吗 可以查看录制的视频
一、zookeeper
kafka用zookeeper来协调集群节点,apache下很多开源产品都是用zookeeper来协调集群节点。![]()
![]()
![]() 知道这么回事就好。本次实战就不讲原理了,感兴趣的小伙伴可以去查资料。跑命令 zkServer.cmd 启动!配置文件:zookeeper-3.4.12\zookeeper-3.4.12-1\conf\zoo.cfg [把zoo_sample.cfg修改成zoo.cfg],用单机模拟的集群,所以后面有带了三个节点配置。纯体验的话,可以去掉,直接跑单机,看到的效果是一样的。
知道这么回事就好。本次实战就不讲原理了,感兴趣的小伙伴可以去查资料。跑命令 zkServer.cmd 启动!配置文件:zookeeper-3.4.12\zookeeper-3.4.12-1\conf\zoo.cfg [把zoo_sample.cfg修改成zoo.cfg],用单机模拟的集群,所以后面有带了三个节点配置。纯体验的话,可以去掉,直接跑单机,看到的效果是一样的。
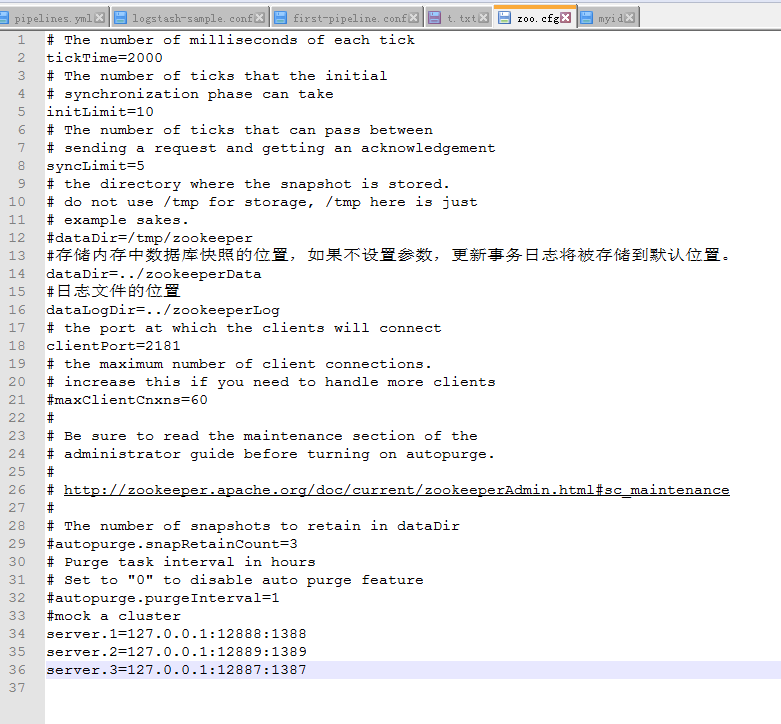
zookeeper_config
#存储内存中数据库快照的位置,如果不设置参数,更新事务日志将被存储到默认位置。
dataDir=../zookeeperData
#日志文件的位置
dataLogDir=../zookeeperLog
#mock a cluster
server.1=127.0.0.1:12888:1388
server.2=127.0.0.1:12889:1389
server.3=127.0.0.1:12887:1387
zookeeper_three_node
偏好配置还需要zookeeper-3.4.12\zookeeper-3.4.12-1\zookeeperData中加一个无扩展名的myid,三个节点可分别取值为1,2,3
zookeeper_three_node_file
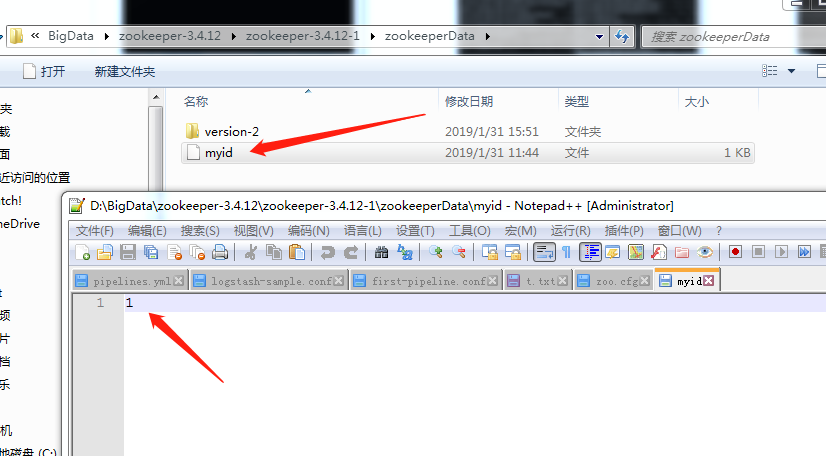
zookeeper_three_node_file_myid
二、Kafka
三个节点,把文件压解出来,先配置好一个,再复制几个,再微调一下。结构如下。因为是单机模拟集群,所以就这么干啦。
打开配置kafka_2.12-2.1.0\kafka_2.12-2.1.0-2\config\server.properties
重点配置敲黑板,注意,单机三个节点的话,端口改成9092,9093,9094,日志文件如果像我一样傻傻的用绝对路径的话,一定要每个点节都加上自己的编号区分开,不然会一直报错!![]()
![]()
![]()
![]()
![]()
关键配置
listeners=PLAINTEXT://:9093
log.dirs=/tmp/kafka-logs-2
启动kafka
kafka-server-start.bat ../../config/server.properties
注意:这里用的是相对路径,跑LogStash的时候也要这么干,网上找到一个教程没有这么干,一直报错
相关命令送上来:
创建主题
kafka-topics.bat –create –zookeeper 127.0.0.1:2181 –replication-factor 1 –partitions 1 –topic dqtest
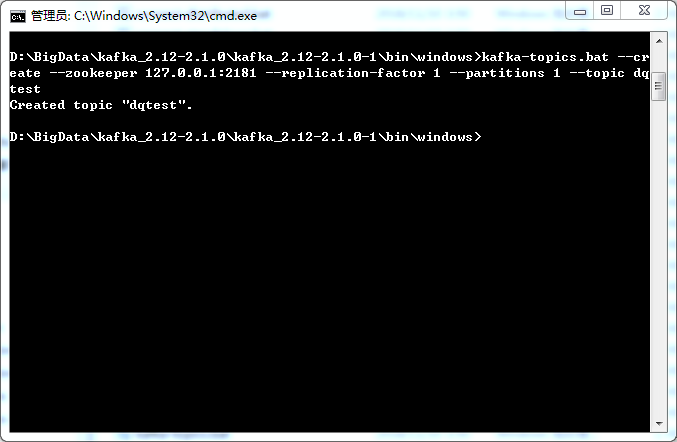
罗列kafka主题
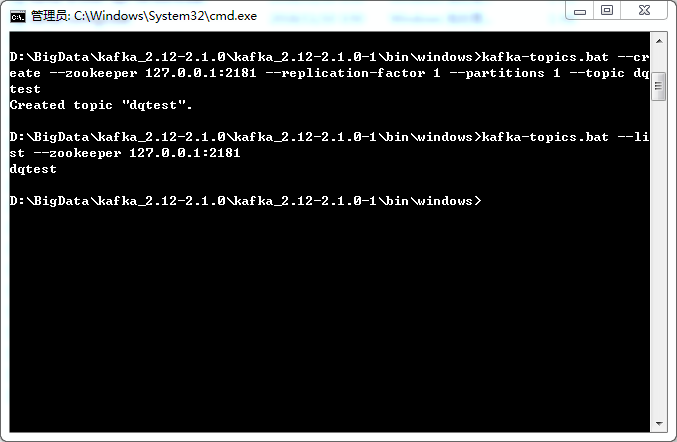
kafka-topics.bat –list –zookeeper 127.0.0.1:2181
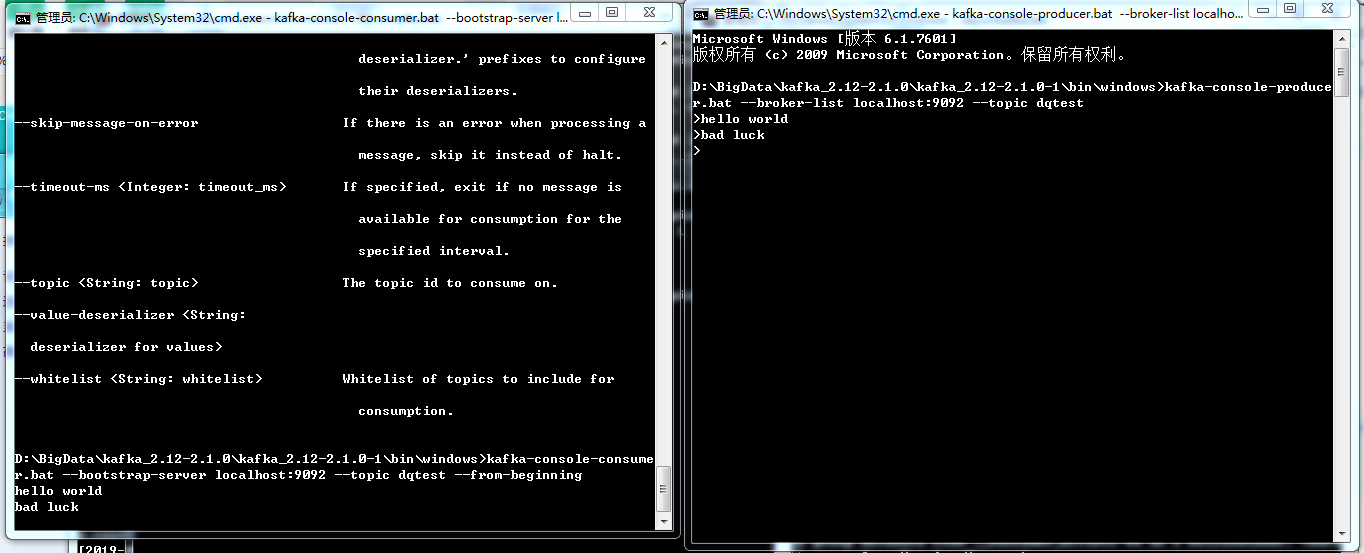
消费topic
kafka-console-consumer.bat –bootstrap-server localhost:9092 –topic dqtest –from-beginning
敲黑板:不同的版本命令有所差异,如果跑不起来,可以核对一下版本对不对。同时,除了搜索,还可以打开config中的文件配置,查看睦一下到底是用的bootstrap-server还是zookeeper,嗯~就是这样子,算是很容易掉坑里的环节。
生产topic消息
kafka-console-producer.bat –broker-list localhost:9092 –topic dqtest
三 LogStash
3.1 填坑之路:报错找不到主类
解决:logstash-6.6.0\logstash-6.6.0\bin\logstash.bat
将55行的 %CLASSPATH% 修改 “%CLASSPATH%”
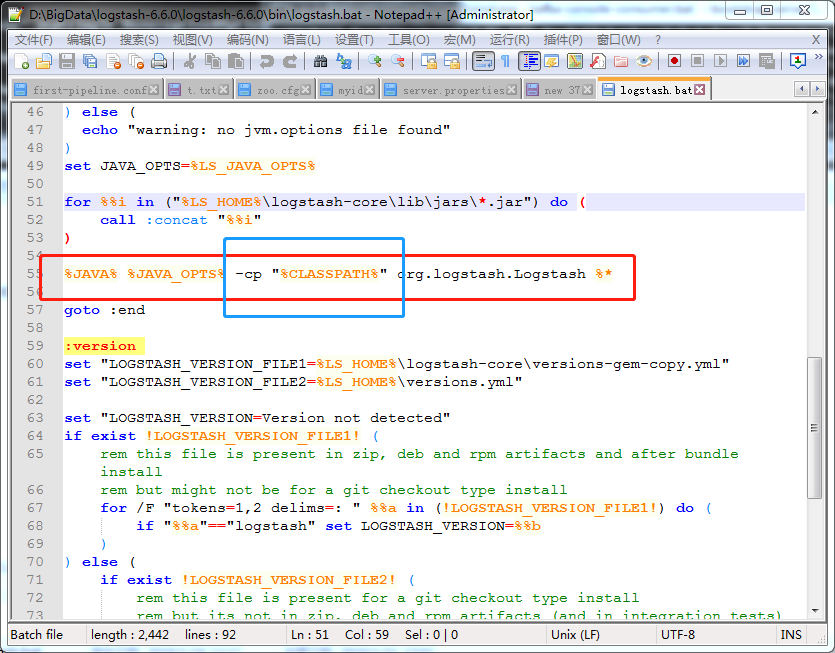
3. 启动命令
logstash -f ../config/first-pipeline.conf –config.reload.automatic
因为找到的资料用的是first-pipeline,所以也跟着敲了,唯一要注意的是,这里记得加上../config/,不然找不到配置文件的。
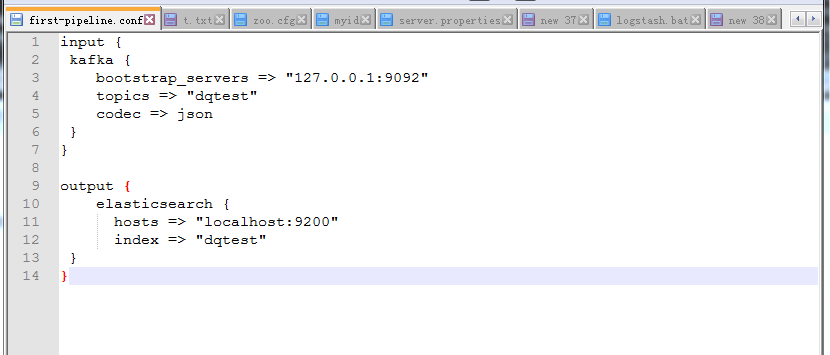
见证奇迹的时刻来了,折腾大半天,最后将FileBeat->Kafka->LogStash->Elasticsearch配通了,结果会是什么样子的呢?
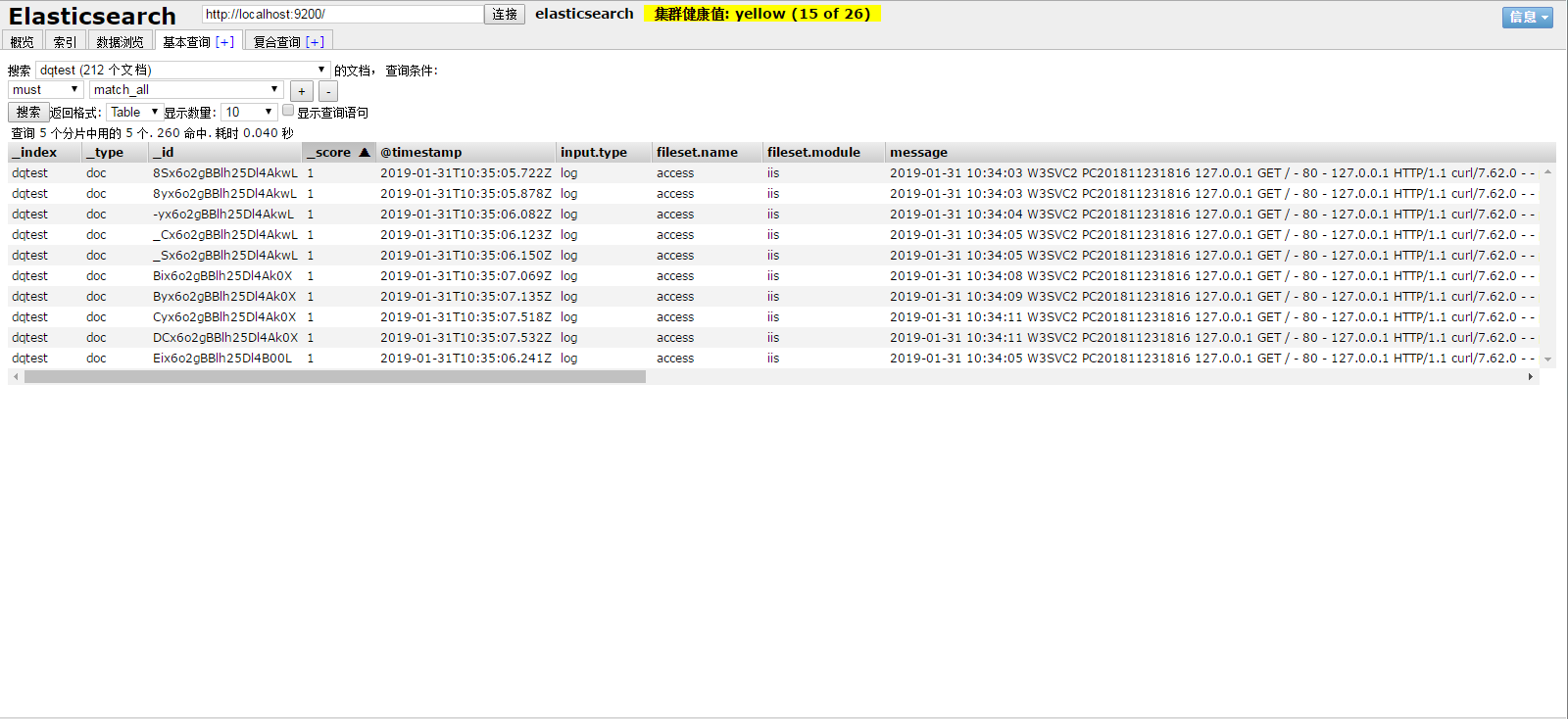
哈哈,就是这样子的啦~今天的实战说真的不太顺利,遇到的小坑都有点意外,其中还需到报路径太长,之前是D:\DQ\xxxx\0008.Job\100010.日志系统\filebeat-6.5.4-windows-x86_64,报错后,修改成了D:\BigData\filebeat-6.5.4-windows-x86_64
明天的大餐是将Storm+MySql配置进来,Storm从Kafka消费数据,将运算结算存到mysql,关注公众号就能收看明天的大型实时日志系统实验总结!期待明天相聚在约吗图文直播间。
