
storm hello world & kafka storm
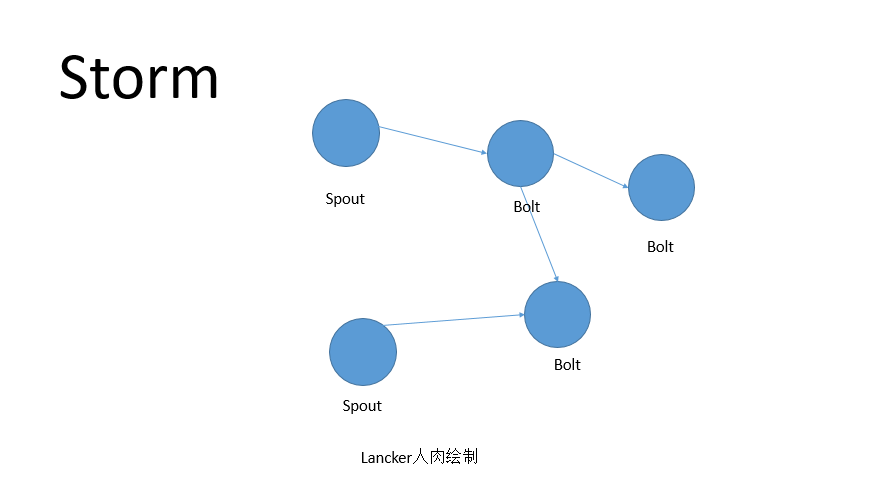
Storm是一个实时计算框架,有开源的大神为我们搭好了平台,按照大神的玩法,Storm的作业是topology,而topolgy是由spout,blot组成,spout是取数据,blot是处理数据,一个topology由一个spout加多个blot组成。将topology丢到storm上就能跑起来,可以在本地模式下跑,也可以在集群模式下跑。
Storm的使用,可以查看小伙伴田海龙的经典Blog示例。一个经典的wordcount示例。这个示范了取数据到处理数据的过程。实际使用Storm的时候, 通常是Storm+kafka,按照我们公司的日志系统的情况来看,是这么搭配。
玩Storm能增值不?
当然可以,提升自身身价。同时,也可以考虑星火理财专业手段直接增值 。新技术能提升个人的技术身价,不过,玩Storm,玩到什么程度又是一个境界了。这个要看如何平衡了。一般日志成型后,可能也不会怎么动了,一直在不断的接触新东西,而storm的源代码读过否?

storm与财富增值
Storm难吗?
如果说使用storm,相对说讲,还是比较easy。比如用storm写一个word count,或者用storm读取kafka的消息。一般来讲,拿来用是比较简单。如果要去深入看storm,就另说了。
Storm如何集成Kafka?
其实有的时候找来找去,很多答案就在github.com上面,Storm的官方源码中,有kafka的集成示范代码,如果看不明白的话,其实也没有很大的关系。因为我们不还可以找国内小伙伴分享的一些经典。
我的经验分享,也是我们结合网上教程实践一些心得。我们知道topology是由spout与bolt组成的,那么跟kafka集成,必然要一个kafkaSpout,这个有现成的,网上的代码只需要实现一个Scheme,对kafka的输出进行转化,把字节流转成字符串。简单的说,kafkaspout别人都写好了。只需要写一个bytebuffer to string的方法。
小坑之一: String 转UTF8
网上的代码报错,找了一段bytebuffer to string替换掉
小坑之二:zookeeper
到底是跟kafka共用一个,还是独立一套zookeeper给storm用。这个问题纠结了一下,因为zookeeper要是每人上集群都配置一套的话,会有好多zookeeper,不过,老司机校友也是这么推荐的,那就听老司机的。单独给storm部署一的大套。插曲:同时听我要zookeeper的同事吓一跳,因为TA觉得是给kafka用的,不想给我这个Storm用。而我们今天只是想把storm与kafka跑通来,并不想再去部署一个zookeeper。哈哈,最好还是蹭的kafka的zookeeper!
关注公众号回复【kafka】可以获得我实战整理的storm连kafka源代码包包哦

有的人写Blog,帖很多代码,都不带写些文字,也有的人喜欢写很多文字,看不到代码。我喜欢全二为一,尽量把自己的一些想法加在里面。还记录一下坑啊什么的,可以查看田海龙的一个入门级demo http://www.tianhailong.com/?p=1358
WordCounter.java:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
package com.youku.demo.bolts;import java.util.HashMap;import java.util.Map;import backtype.storm.task.TopologyContext;import backtype.storm.topology.BasicOutputCollector;import backtype.storm.topology.OutputFieldsDeclarer;import backtype.storm.topology.base.BaseBasicBolt;import backtype.storm.tuple.Tuple;public class WordCounter extends BaseBasicBolt { Integer id; String name; Map<String, Integer> counters; /** * At the end of the spout (when the cluster is shutdown * We will show the word counters */ @Override public void cleanup() { System.out.println("-- Word Counter ["+name+"-"+id+"] --"); for(Map.Entry<String, Integer> entry : counters.entrySet()){ System.out.println(entry.getKey()+": "+entry.getValue()); } } /** * On create */ @Override public void prepare(Map stormConf, TopologyContext context) { this.counters = new HashMap<String, Integer>(); this.name = context.getThisComponentId(); this.id = context.getThisTaskId(); } public void declareOutputFields(OutputFieldsDeclarer declarer) {} public void execute(Tuple input, BasicOutputCollector collector) { String str = input.getString(0); /** * If the word dosn't exist in the map we will create * this, if not We will add 1 */ if(!counters.containsKey(str)){ counters.put(str, 1); }else{ Integer c = counters.get(str) + 1; counters.put(str, c); } }} |
WordNormalizer.java:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
package com.youku.demo.bolts;import backtype.storm.topology.BasicOutputCollector;import backtype.storm.topology.OutputFieldsDeclarer;import backtype.storm.topology.base.BaseBasicBolt;import backtype.storm.tuple.Fields;import backtype.storm.tuple.Tuple;import backtype.storm.tuple.Values;public class WordNormalizer extends BaseBasicBolt { public void cleanup() {} /** * The bolt will receive the line from the * words file and process it to Normalize this line * * The normalize will be put the words in lower case * and split the line to get all words in this */ public void execute(Tuple input, BasicOutputCollector collector) { String sentence = input.getString(0); String[] words = sentence.split(" "); for(String word : words){ word = word.trim(); if(!word.isEmpty()){ word = word.toLowerCase(); collector.emit(new Values(word)); } } } /** * The bolt will only emit the field "word" */ public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("word")); }} |
WordReader.java:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
|
package com.youku.demo.spouts;import java.io.BufferedReader;import java.io.FileNotFoundException;import java.io.FileReader;import java.util.Map;import backtype.storm.spout.SpoutOutputCollector;import backtype.storm.task.TopologyContext;import backtype.storm.topology.OutputFieldsDeclarer;import backtype.storm.topology.base.BaseRichSpout;import backtype.storm.tuple.Fields;import backtype.storm.tuple.Values;public class WordReader extends BaseRichSpout { private SpoutOutputCollector collector; private FileReader fileReader; private boolean completed = false; public void ack(Object msgId) { System.out.println("OK:"+msgId); } public void close() {} public void fail(Object msgId) { System.out.println("FAIL:"+msgId); } /** * The only thing that the methods will do It is emit each * file line */ public void nextTuple() { /** * The nextuple it is called forever, so if we have been readed the file * we will wait and then return */ if(completed){ try { Thread.sleep(1000); } catch (InterruptedException e) { //Do nothing } return; } String str; //Open the reader BufferedReader reader = new BufferedReader(fileReader); try{ //Read all lines while((str = reader.readLine()) != null){ /** * By each line emmit a new value with the line as a their */ this.collector.emit(new Values(str),str); } }catch(Exception e){ throw new RuntimeException("Error reading tuple",e); }finally{ completed = true; } } /** * We will create the file and get the collector object */ public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) { try { this.fileReader = new FileReader(conf.get("wordsFile").toString()); } catch (FileNotFoundException e) { throw new RuntimeException("Error reading file ["+conf.get("wordFile")+"]"); } this.collector = collector; } /** * Declare the output field "word" */ public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("line")); }} |
TopologyMain.java:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
package com.youku.demo;import com.youku.demo.bolts.WordCounter;import com.youku.demo.bolts.WordNormalizer;import com.youku.demo.spouts.WordReader;import backtype.storm.Config;import backtype.storm.LocalCluster;import backtype.storm.topology.TopologyBuilder;import backtype.storm.tuple.Fields;public class TopologyMain { public static void main(String[] args) throws InterruptedException { //Topology definition TopologyBuilder builder = new TopologyBuilder(); builder.setSpout("word-reader",new WordReader()); builder.setBolt("word-normalizer", new WordNormalizer()) .shuffleGrouping("word-reader"); builder.setBolt("word-counter", new WordCounter(),1) .fieldsGrouping("word-normalizer", new Fields("word")); //Configuration Config conf = new Config(); conf.put("wordsFile", args[0]); conf.setDebug(true); //Topology run conf.put(Config.TOPOLOGY_MAX_SPOUT_PENDING, 1); LocalCluster cluster = new LocalCluster(); cluster.submitTopology("Getting-Started-Toplogie", conf, builder.createTopology()); Thread.sleep(2000); cluster.shutdown(); }} |
pom.xml:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" <modelVersion>4.0.0</modelVersion> <groupId>com.youku.demo</groupId> <artifactId>demo-storm</artifactId> <version>0.0.1-SNAPSHOT</version> <packaging>jar</packaging> <name>demo-storm</name> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> </properties> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>2.3.2</version> <configuration> <source>1.6</source> <target>1.6</target> <compilerVersion>1.6</compilerVersion> </configuration> </plugin> </plugins> </build> <repositories> <!-- Repository where we can found the storm dependencies --> <repository> <id>clojars.org</id> </repository> </repositories> <dependencies> <!-- Storm Dependency --> <dependency> <groupId>storm</groupId> <artifactId>storm</artifactId> <version>0.8.0</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>3.8.1</version> <scope>test</scope> </dependency> </dependencies></project> |
words.txt:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
|
stormtestaregreatisanstormsimpleapplicationbutverypowerfullreallyStOrmisgreat |
运行的时候需要配置参数:src/main/resources/words.txt
因为入门的wordcount单独展示的,会给人感觉没有太大的实用价值。将kafka与storm的放一起,可以更好的理解怎么与kafka集成。
关注公众号回复【kafka】可以获得我实战整理的storm连kafka源代码包包哦。
赞助商小伙伴链接:
如何享受宜信星火金服宜心理财:
- 扫码二维码
- 通过宜信星火金服活动链接 http://www.ixinghuo.com/qcode.php?yixinqcode
- 通过宜信星火金服理财师店铺链接:https://xinghuo.yixin.com/yiidea
- 通过宜信星火金服理财师移动端邀请页面 https://xinghuo.yixin.com/mobile/activityPage/shareShop/yiidea
5.通过宜信星火金服理财师店铺宜心理财团队短链接:
- 通过宜信星火金服宜心理财团队网站页面